What is the Difference Between Easy Medium and Hard Bots Overwatch
Bot realtime object detection in Overwatch on Ubuntu 18.04
In this tutorial, I will told you, how to install Overwatch, gather data in images from your actually gameplay, train model on it and apply this model to realtime object detection.
For doing that, ensure that you have installed Tensorflow. Preferably with GPU support for more speedup. Without that you will have smaller fps, training the model will take a fair amount of time and realtime performance may be not achievable.
Part1: Install Overwatch on Ubuntu 18.04
After few unsuccessfull attempts to install Overwatch using Wine and DXVK I am come for Flatpak, which seems very easy to run Windows apps on Linux. And so it is, except for a special moment with driver versions. More on this later.
Running those commands above installed Flatpak and Battle.net launcher:
sudo apt install flatpak gnome-software-plugin-flatpak
sudo flatpak remote-add --if-not-exists flathub https://dl.flathub.org/repo/flathub.flatpakrepo
sudo flatpak remote-add --if-not-exists winepak https://dl.winepak.org/repo/winepak.flatpakrepo
sudo flatpak install winepak com.blizzard.Overwatch And after reboot PC type:
sudo flatpak run com.blizzard.Overwatch and you will see that:
For the more FPS and smooth experience you will need to install additional nvidia drivers (because now game worked using OpenGL engine). In a few cases game will not run without graphical drivers at all.
Important: version of your current output from nvidia-smi command and flatpak version must be the same. Otherwise, you will get error when clicking on Play at Overwatch section in Battle.net launcher. And be ware, that's you need both version of Flatpak drivers.
For example, currently I have this version of nvidia drivers:
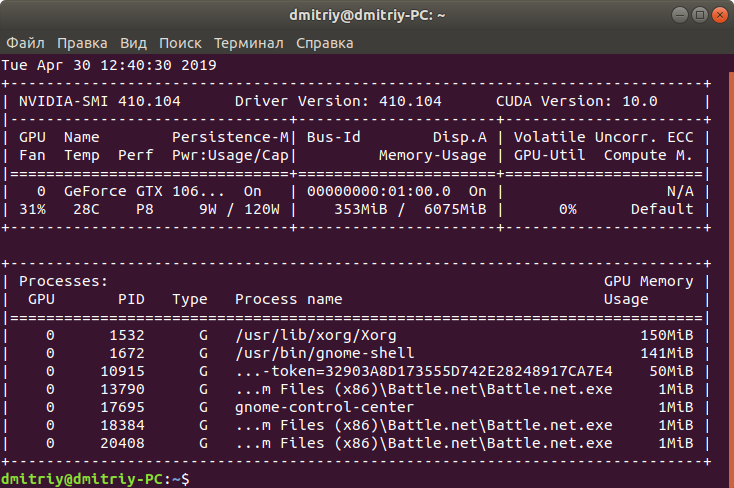
Next step: I check if there is a driver for this version in Flatpak:
flatpak remote-ls flathub | grep nvidia And yep, at FlatHub there is 410–104 version of Nvidia runtime packages (don't place screen here because of huge output).
So I can then use those commands to install 32 and 64 bit versions in Flatpak (remind, that you need both versions!):
flatpak install flathub org.freedesktop.Platform.GL32.nvidia-410–104
flatpak install flathub org.freedesktop.Platform.GL.nvidia-410-104 And if everything worked out you can start the game!
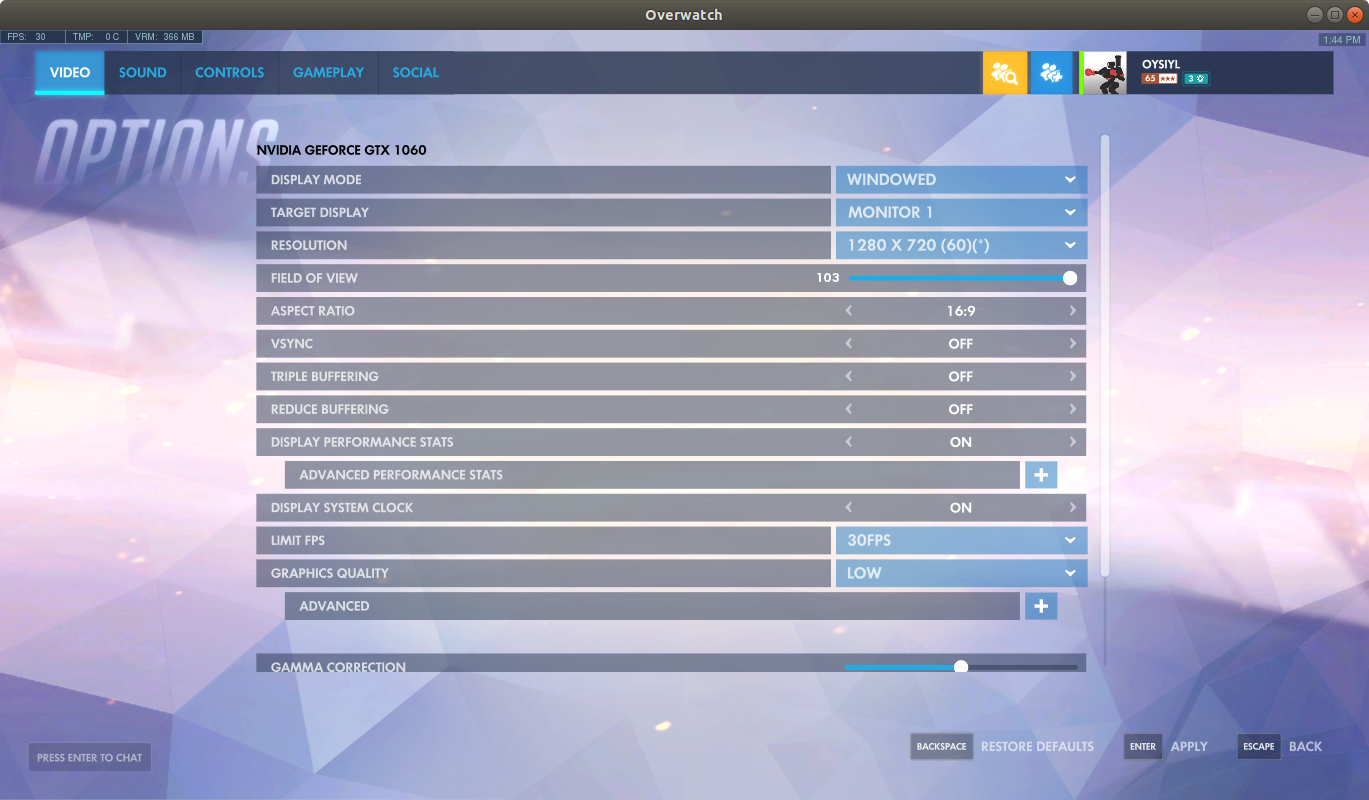
And last: for recording and getting more comfortable fps go to Options-Video and select a windowed mode, 1280*720 resolution, 30 fps lock and low settings . This allow you to achieve around 30/3 = 10 fps performance in game when model will working together while you are playing Overwatch. Yep, running model is exhaustive process and your GPU will worked on 100% . It depends on your GPU, actually. But on my 1060 it is true.
In next parts of this tutorial I will show you how to get training data for your model, train model(if you want) and make real-time detection when playing.
P.S.: If you stuck on choosing the right driver, please check this small article (you can found there more explanations too) how to overcome this problem:
Part2: Record gameplay and prepare images for training
Let's install those libraries, which allows us to capture game:
pip3 install --user pyscreenshot
pip3 install --user mss After installing Overwatch you can recording gameplay in real-time (around 80–100 fps) using simplestream.py.
Look at line 17: here you select part of the screen to capture. You need to fit your window game's with values in monitor dictionary. Feel free to replace this line of code with values, with which you will are most comfortable. For example, I hardcoded them and fit Overwatch window in center of a screen; you might to prefer place window at the top left corner etc. Spend few minutes on it; you will do it only once.
Just type in console:
python3 simplestream.py and return to game. When you will done, click on window frame and press Q. Script was finished and you can see output.avi file here. That's your gameplay, on which model will be trained.
Important: For the first time you can use trained model from my repo and don't make images, training model etc (so skip this and go to the next part). If you will be inspired by results, welcome to training your own model on your own data.
Get images
For extracting frames from output.avi you will need ffmpeg: so let's install it!
pip3 install --user ffmpeg Use ffmpeg to get frames from the created video (create folder /images first!):
ffmpeg -i output.avi -vf fps=10 images/thumb%04d.jpg -hide_banner This get us 10 frames for each seconds from a video output.avi, and save those frames(images) in folder images.
Resize with python3 resizer.py
You can use now resizer.py to make pictures more smaller than now.
python3 resizer.py I commented line 20, because found, that resolution 960*540 works the best for pictures with initial resolution around 1280*720. Pss! Line 20 and 21 make the same thing, so you can use which line you like the most). But don't forget to comment another line — or your broke your images!(just kidding — in that case you resize each images two times and got a very terrible results).
Annotate with labelImg
Let's annotate images. For this I am suggest using labelImg.
git clone https://github.com/tzutalin/labelImg.git
cd labelImg
sudo apt-get install pyqt5-dev-tools
sudo pip3 install -r requirements/requirements-linux-python3.txt
make qt5py3
python3 labelImg.py Why not pip3 install labelImg? Because I'm tried it and can't just launch this program. So install from source is only one way, which worked for me. And you can try install from pip3, maybe you can launch this and save another few minutes on it.
I annotated images using one class — "bot", because I want to detect bots (obviously, isn't?). If you want to detect many classes — time, consumed on this part, will increase very much because your chance to mistake and select wrong class be very high (especially when you have many objects on frame).
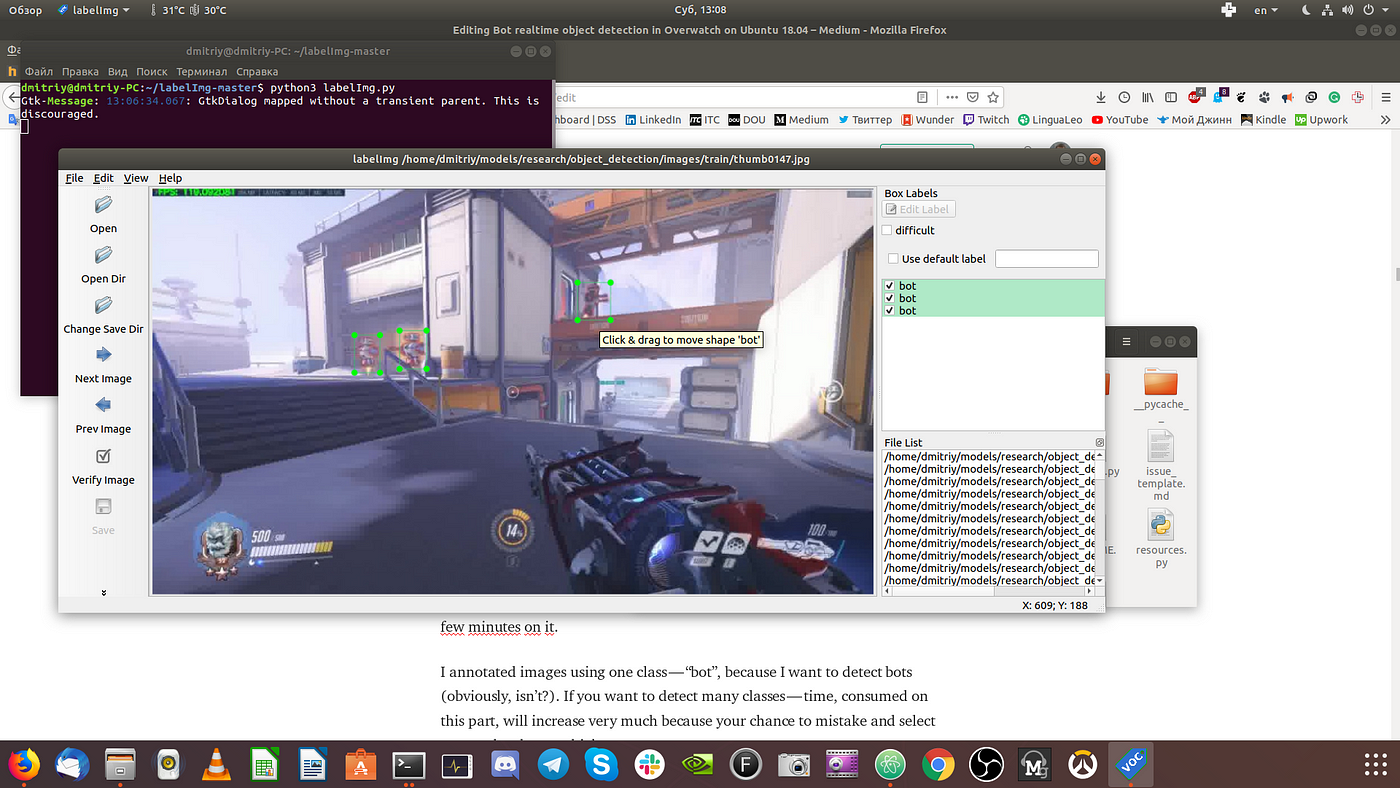
So, now you need to annotate each image in images/train and images/test folders. It's time consuming part, so be calm, attentive and don't move fast.
Important: Delete bad frames without at least one class on it. If you miss at least one file you can't create annotations for this image. And model training will not yet started, because you will have not equal amount of images and xml files (annotations)!
Create test and train directories
For this, using split.py:
python3 split.py Code from this script:
After that place images folder in object_detection folder and go to tensorflow part (Part 3).
Part3: Tensorflow part
You can skip this part and use my trained model (I provided all the files at a github repo) for the first time. In both cases you will need to install those libraries:
pip3 install pillow
pip3 install lxml
pip3 install jupyter
pip3 install matplotlib
pip3 install opencv-python opencv-contrib-python
sudo apt install protobuf-compiler This part is the most time consuming and you can stuck on many problems during this process. My guide based on awesome tutorial from here. It for the windows 10, but the differences are not so much. And only if you want to train own model on your own data (such detect Hanzo from quickplay match) you might to do all of this steps below.
Download models, reload protos, reload variables (don't forget to change /home/dmitriy to /home/*your_username*/):
git clone https://github.com/tensorflow/models.git
cd models-master/research
protoc object_detection/protos/*.proto — python_out=.
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
sudo gedit ~/.bashrc
export PYTHONPATH=$PYTHONPATH=/home/dmitriy/models/research:/home/dmitriy/models/research/slim
source ~/.bashrc From research directory:
sudo python3 setup.py build
sudo python3 setup.py install Then run (after annotating all of the images):
python3 xml_to_csv.py This creates a train_labels.csv and test_labels.csv file in the \object_detection\images folder. Make changes in generate_tfrecord.py. For example, my file:
As you see, you need to change at line 30–35 all with your classes (in my case 'bot'). All others you don't need to change.After that (from object_detection folder):
python3 generate_tfrecord.py --csv_input=images/train_labels.csv --image_dir=images/train --output_path=train.record
python3 generate_tfrecord.py --csv_input=images/test_labels.csv --image_dir=images/test --output_path=test.record These generate a train.record and a test.record file in \object_detection. These will be used to train the new object detection classifier.
Download model from tensorflow zoo as config and put in object_detection/training folder:
wget http://download.tensorflow.org/models/object_detection/faster_rcnn_inception_v2_coco_2018_01_28.tar.gz
tar xvzf faster_rcnn_inception_v2_coco_2018_01_28.tar.gz Make changes in labelmap.pbtxt. For example, my file:
So, for example, if you want to detect Hanzo class, rename bot to Hanzo.
Make then changes in faster_rcnn_inception_v2_pets.config.
Code:
Here we go:
change at line 9 num_classes to total number of your classes. For example, if I want to detect just one bot it would be 1;
change at line 106 fine_tune_checkpoint to path where your faster_rcnn_inception_v2_pets.config is placed;
change at line 112 nums_steps to how much you want to train the model (usually, 10–20k is enough);
change at line 122 input_path to where your train.record is;
change at line 124 label_map_path to where your labelmap.pbtxt is;
change at line 128 num_examples to the number of images you have in the \images\test directory;
change at line 136 input_path to where your train.record is;
change at line 138 label_map_path to where your labelmap.pbtxt is.
Be careful to change those paths correctly!
And place those files(labelmap.pbtxt and faster_rcnn_inception_v2_pets.config) in training folder.
Move train.py from legacy to main folder.
After that you can start training:
python3 train.py --logtostderr --train_dir=training/ --pipeline_config_path=training/faster_rcnn_inception_v2_pets.config tensorboard --logdir='training' Be sure that inference_graph is empty or not created.
python3 export_inference_graph.py --input_type image_tensor --pipeline_config_path training/faster_rcnn_inception_v2_pets.config --trained_checkpoint_prefix training/model.ckpt-10000 --output_directory inference_graph Feel free to change model.ckpt-number_of_epochs to your number. So, if your trained for 1000 epochs, change trained_checkpoint_prefix training/model.ckpt-10000 to trained_checkpoint_prefix training/model.ckpt-1000.
This creates a frozen_inference_graph.pb file in the \object_detection\inference_graph folder. The .pb file contains the object detection classifier.
For the next part of tutorial you need frozen_inference_graph and labelmap.pbtxt from \object_detection\training folder. Also faster_rcnn_inception_v2_pets.config, folder protos, utils, training and core.
So create object_detection folder somewhere and move all of that into it. For now you prepared to the last part (Part 4: Realtime detection).
Part4: Run realtime detection
After all the hard work above, this step become one of the easiest.
If you just want tested trained model, then download my repo using this command:
git clone https://github.com/Oysiyl/Bot-object-detection-in-Overwatch.git Then rename this folder to object_detection and move to this folder.
I suggest you for the first time run Object_detection_image.py — to ensure, that everything works fine. So run those:
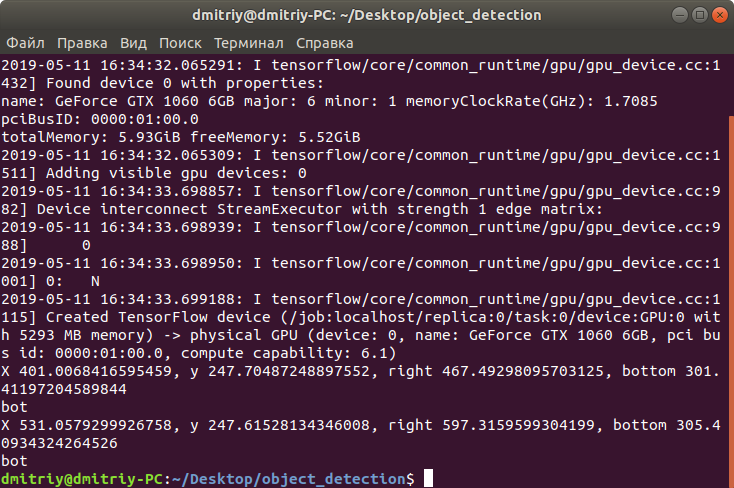
python3 Object_detection_image.py And after around 5–10 seconds waiting for initializing Tensorflow and loading model into GPU memory, you will see this picture with recognized two boxes(press Q to exit):

Along with coordinates of detected boxes:
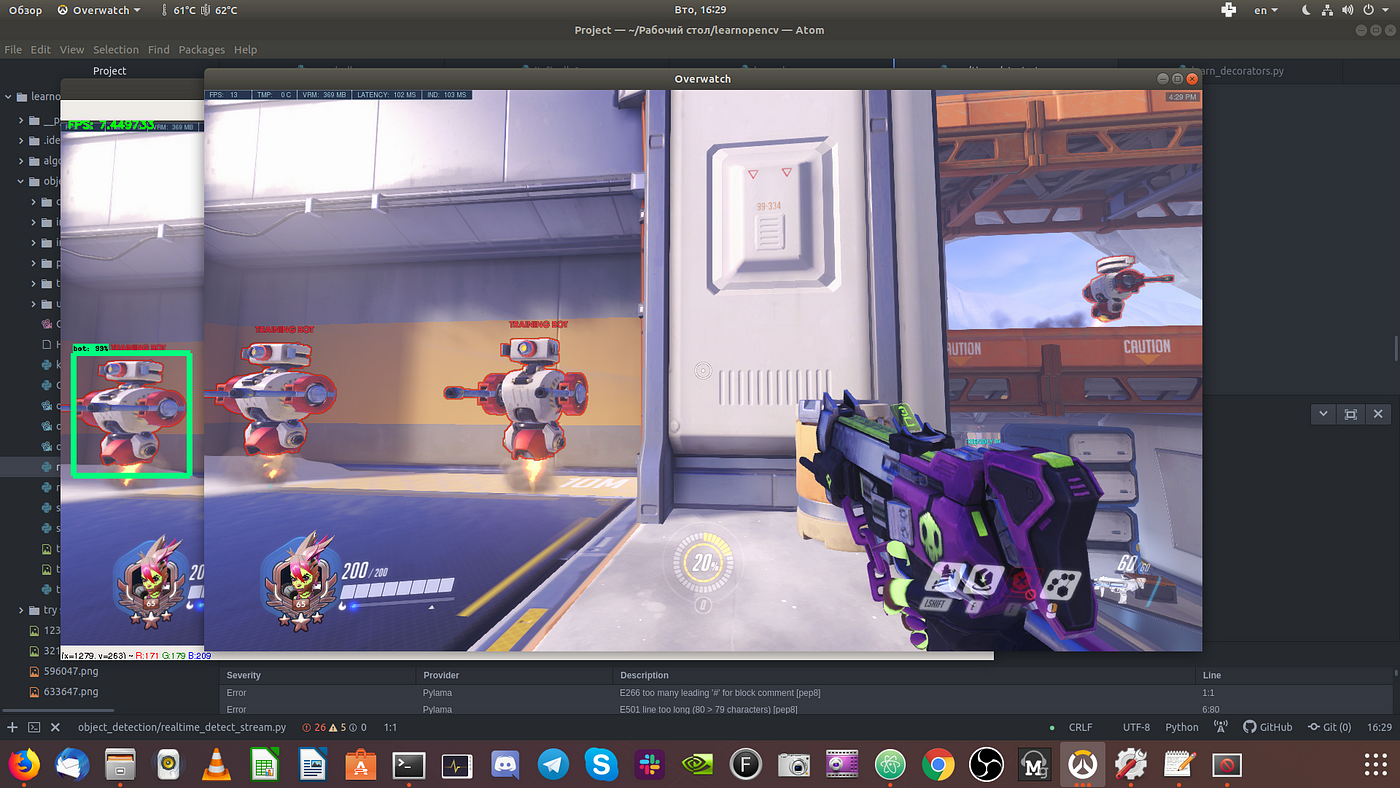
Code from script, which we will run after (realtime_detect_stream.py):
Run realtime_detect_stream.py (for exit click on frame window and press Q):
python3 realtime_detect_stream.py Experience be more comfortable, if you have ultrawide monitor or just a second one. You will see realtime object_detection! I can't show here a nice screen because I have only one FullHD monitor and on it actually the game window and window with recognized game are not fit.
Small tip: you can change 123 line to cv2.resize(img, (300, 300)) and get more robust picture (or select more small amount of pixels):
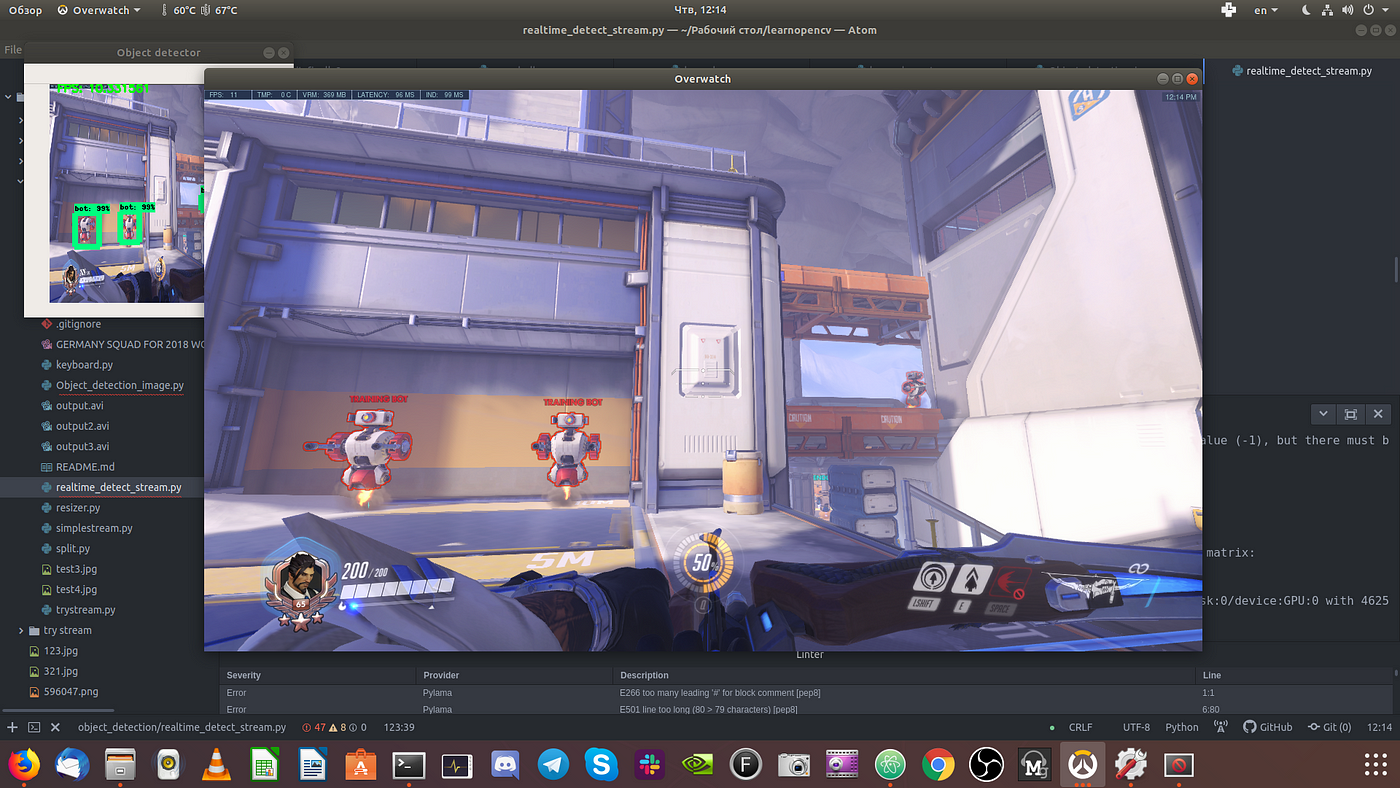
After exit you see that a file output2.avi has created. Here you can see video and see how well model will performed:
Extra part: Defeat the bots using trained model
Psss! After determining who is your enemy you can defeat him. So, opencv can detect coordinates of boxes with bots. And you can use pyautogui for defeating them!
pip3 install --user pyautogui
sudo apt-get install python3-tk python3-dev Different distances have a significant effect on accuracy. Look at this demonstration:
And this from larger distance (I am using WASD to go near the targets):
I tested it on the Widowmaker. So, the delay in one second allows her to aim and make a powerful shot instead of a weak shot without delay. You just walk toward the bot, opencv detect bot and build a box around him, and after that program try to make a shot. I made the point with possible position of the head in the box, so program will keep move camera to this point and click after achieving that point.
Be ware, that using time.sleep(1.0) cause losing 1 second in recording video, because program paused for 1 second (10 fps). You can change this line with time.sleep(1.0) to pyautogui.PAUSE=1.0 and added after click returns to default pyautogui settings (by following way — pyautogui.PAUSE=0.01). I shouldn't recommend you this because programm accuracy will make some strange moves (such as shoot when moving toward the target point). Advantage using those method — your recording video will be complete, without losing 10 fps (1 second) each time when you take aim.
Important: for correct actions from pyautogui you need to change in game Options-Video-Display Mode and set to "Borderless Windowed". Without that program can not correctly clicking and moving your camera in randomly position each time. Don't forget that if you want to record this, you need change monitor dictionary (look at line 116), because your game window now will be borderless windowed instead of windowed before this.
This code insert in realtime_detect_stream.py after the name definition. If you can't figure it out where to add, look at this complete example:
Short explanation by important lines of code:
In line 152 we are selected only boxes, which pass 90% limit detection; lines 167–181 — found coordinates for boxes; using if statement (lines 183–185) need for select and track only one boxes per frame. It's important, because if model detect two or more boxes she will jumped from one to another without any actions (but it works not perfect and something buggy).
Then we found centerX and centerY coordinates — to this point our model will move. For moving calculated moveX and moveY. If move very big (line 191–194) we are make this move smaller — that improve accuracy of moves along with (line 195–198): if model are close (5 px or smaller) to target, make next move equal to 0(so no move on this axis will allowed, move on another axis which is great then 5). If we achieved "center" — model will perform our supposed set of actions (line 204–212). Here you can try used pyautogui.PAUSE along without time.sleep(1.0). If we not achieved "center" yet, then perform moves based on coordinates of current camera position (lines 214–226).
In next line for each frame draw a circle (point to which we want to move), and make many texts output, placed them directly on your frame for further monitoring (this is very-very helpful, when something going wrong). For example, when defeat_bots.py moves are not undestandable by you, those monitoring outputs can helps you to see, what model will do in next frame, which moves select, in which directions moves next, how much pixels... You can comment those outputs (lines 232–237).
And at line 240 opencv saved given frame to video, and then show you this frame (line 241). As always, press Q on keyboard will stop program and after saving video(line 250) opencv will close (line 251).
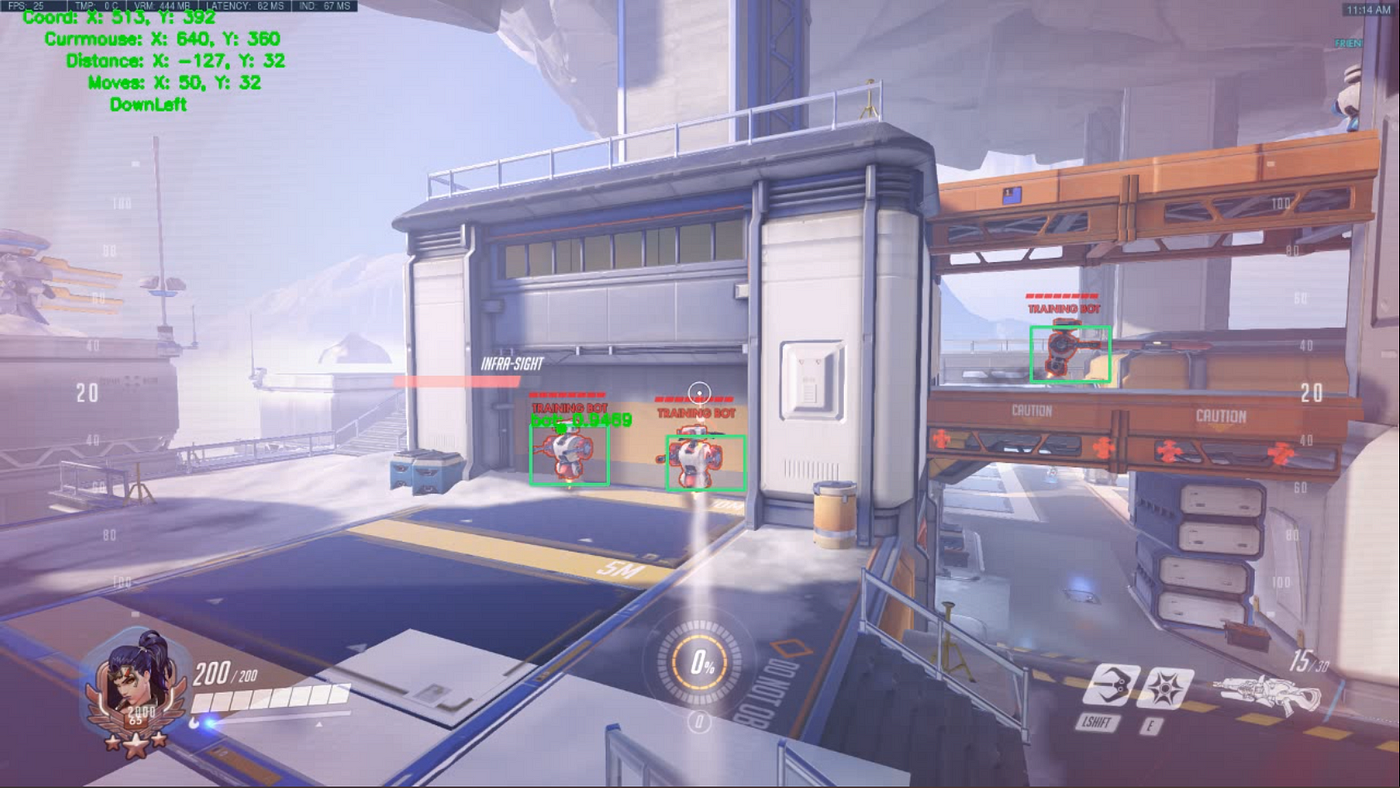
As you see from image below, model shot bot at the center and begin move toward next target. And it's me activated ult, program can't do that right now. I just be curious if ult having effort on model accuracy (and don't found any). And I performed all the moves by character using WASD combination.
Run defeat_bots.py:
python3 defeat_bots.py As usually, go to Overwatch in training room. If opencv detects at least one bot— program will move camera using mouse to this recognized bounding box and clicked until box are disappeared(bot are defeated). Yeahyy!
Bonus: It is not hard to test it on other heroes vs bots in training room. For example, changing actions at lines (204–212) to only pyautogui.click() allow you used such character, which main attack is left click:
As you see, detection is not depend on selected hero, and you can adopt script for almost any hero you want, taking into account differences in the gameplay of hero and which abilities he/she have.
Important: all in this article, especially extra part made with scientifically purpose and my curiosity. I am not recommended you used model against other players, because:
Zero: Model can't detect when object is far away or hero see only part of objects. You need to train model understand effects (such as Reinhardt shield or ultimative ability each hero).
First: because you need to train model on around thousand (!!!) classes to recognize each hero (around 30 now) on each skin (don't know how much).
Second: you needed to train on many different maps (model, trained on Oasis will almost not work on Antarctica because of different environment).
Third: my dataset with almost 600 images trained on 1000 steps should be enough for detect one class (bot) on one map without any skin (but you see this detection is far from ideal). Imagine, how much images you need to create and annotate to achieve something good. And how much computational power you will need for training to get good results and to achieve at least 60 frames per second in realtime.
Fourth: Model can't move! I don't know logic how to implement this now.
Also, because it is cheating and you should probably be banned, when playing with real people, not bots.
Hope you succeed and this work will inspire you to make more interesting model from this game or another (which you enjoy the most).
Have a nice day, you have deserved it!
Source: https://towardsdatascience.com/bot-realtime-object-detection-in-overwatch-on-ubuntu-18-04-5571c4c85ec6
0 Response to "What is the Difference Between Easy Medium and Hard Bots Overwatch"
Post a Comment